The difficult problem of understanding the relation between bias in language models and human biases
Artificial Intelligence (AI) is a technology that is here to stay. In many aspects of daily life, one interacts with AI algorithms in one way or another. These algorithms range from search engines like Google, that present search results in a way that hopefully is optimal to you, to health apps that aim to support your healthy living habits. Because of your omnipresent interactions with AI, it is important to understand how AI systems make decisions. This is especially true, since we need to be able to trust those decisions to be fair and unbiased.
A clear case where there is a danger for unfairness and bias in AI systems is in the use of large language models. Roughly, these models aim to capture the meaning of natural language expressions; They are used in many domains, including automatic translation, speech recognition, and chat bots. Obviously, it is crucial that these models get the meaning right, and do not introduce unfair biases in the meaning of a phrase!
What makes a bias unfair? The way that most language models express the meaning of the word “nurse” is highly associated with the way feminine terms (woman, girl, she, etc) are expressed. This does not seem to be what we want, since a male nurse has the same job characteristics as a female nurse. However, this bias, and similar gender biases related to professions, does express the gender gap. In fact, the size of the gender gap in terms of labor statistics over the years has been shown to predict the bias in language over the years. Even stronger, implicit biases that humans seem to have about (among other things) gender, are reflected in language models as well. It seems thus that to some extent language models reflect societal trends, and nothing else. Should we hold these AI algorithms to a higher standard than we do humans? Or should we strive to eradicate bias from language, and consequently from human vocabulary and thought? To answer these questions, an understanding of human bias is necessary as well.
Understanding human biases comes with its own set of problems. Some people may be more biased than others, but how do we measure such a difference? First, it is important to realize that the question implies a golden standard. There could be people out there that are completely unbiased! But what would their behavior and decisions look like? This is a normative question, that society has to address. Second, in order to measure a difference, there need to be good measurement tools. Contrary to many physical properties such as length or weight, there is no precise measurement tool for human bias.
One of the reasons may be that human biases and attitudes are inherently personal, and it is extremely difficult to develop tests that allow for the heterogeneity of biases that are induced by images, words, or names. For example, we are currently running a study to show that biases that have been reported in past studies (e.g., towards women) may depend on the use of specific words (as in the image below), rather than show an implicit bias towards women per se.
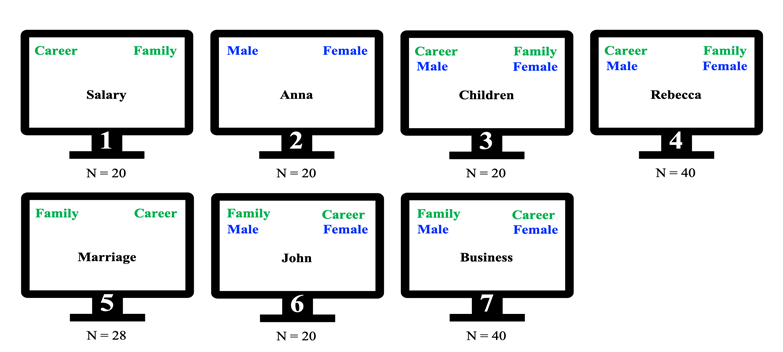 In the Gender-Career Implicit Association Test, people have to press a
right or a left button in response to either gender names or two
supposedly gender-stereotypical categories (Career and Family). The idea
is that this is harder when there is a “mismatch” between the category
and the gender that require the same button press.
In the Gender-Career Implicit Association Test, people have to press a
right or a left button in response to either gender names or two
supposedly gender-stereotypical categories (Career and Family). The idea
is that this is harder when there is a “mismatch” between the category
and the gender that require the same button press.
This is the challenge our research group stands for: To understand how bias in large language models relates to bias in humans. We thus need to address fundamental questions about the nature and measurement of such biases. A daunting challenge for sure, but the end goal is extremely worthwhile: To mitigate unfair biases in the AI systems we interact with on a daily basis, such that we can gain trust in their decisions, and fairness is achieved.